
How You Can Use Git Reference Repository to Reduce Jenkins’ Disk Space
Multibranch pipelines, which often include many git branches, may result in the checkout of the very same “.git” directory on the File System. To avoid this duplication, you can configure the Jenkins Git Plugin to use a reference repository as a cache in order to reduce remote data transfer and local disc usage.
The problem
While many administrators tend to use Jenkins as their main Continuous Integration Tool, day-to-day work becomes quite struggling. Quiet often, developers may complain about longer build intervals, storage will fill up and networking traffic becomes much busier. When working with heavy git repositories, these symptoms become ever more severe.
We encountered that exact same issue when we saw that Jenkins’s PV (as we run Jenkin on a GKE cluster) fills up. After analyzing the Jenkins mount directory we came to the conclusion that we have many “.git” directories, which in our case resulted in freeing up about 40% of disk space! An even deeper examination of our Jenkins workspaces folder led to the conclusion that the same “.git” directory is duplicated across many of the same project’s branches in our system.
Another problem this situation may cause is increased data traffic between Jenkins nodes and the Git server. Especially in cloud-native environments, this increased traffic may result in extra costs.
So why does it happen?
First case may be using Multibranch Pipelines which is one of the most used Jenkins job types. The Multibranch Pipeline project type enables you to implement different Jenkinsfiles for different branches of the same project. In a Multibranch Pipeline project, Jenkins automatically discovers, manages and executes Pipelines for branches which contain a Jenkinsfile in source control.
Another example which may cause the same problem, is when you have one Git repo, with many sub-modules which all include in the same dir. Once you create a Jenkins job for each of the modules, inevitably, you will check out the same repository multiple times.
Optional – How to inspect the problematic git repos?
- Option #1: use the “ncdu” tool to examine your FS.
- Install ncdu tool
- Cd into the $JENKINS_HOME/workspace
- Run “ncdu”. This may take several minutes to come up.
- Inspect the Jenkins workspace to look for git projects which have heavy “.git” dirs downloaded.
- Option #2: Find all “.git” dirs in the workspace
- Cd into the workspace dir:
- cd $JENKINS_HOME/workspace
- Run
- find . -name .git -type d -exec du -sh {} ;
- This will give you an overview about the number of times you download the same “.git” for the same project.
- Cd into the workspace dir:

The solution – configure git reference repo
So what is Git Reference Repository?
Git reference repository is “a local bare repository whose content is used instead of copying from the remote repository.” (Link). It therefore simplifies the process of cloning the repository every time, which results in both: reduced disk space and reduced network traffic.
- Let’s take as an example a large git project. I created the sample-tomcat-netanelkoli repo to demonstrate a simple helm chart sample to deploy tomcat with an initial apache-tomcat8 app. In addition, I uploaded a 10M sample file to increase its size.
- Navigate to your Jenkins URL and enter the Installed Plugins page. https://<JENKINS_URL>/pluginManager/installed . Make sure the Git Plugin is installed.
- Create a demo build for this project:
- In Jenkins select: “New Item”. Select “Pipeline” job type and in pipeline name enter: “git_reference_repo_demo”.
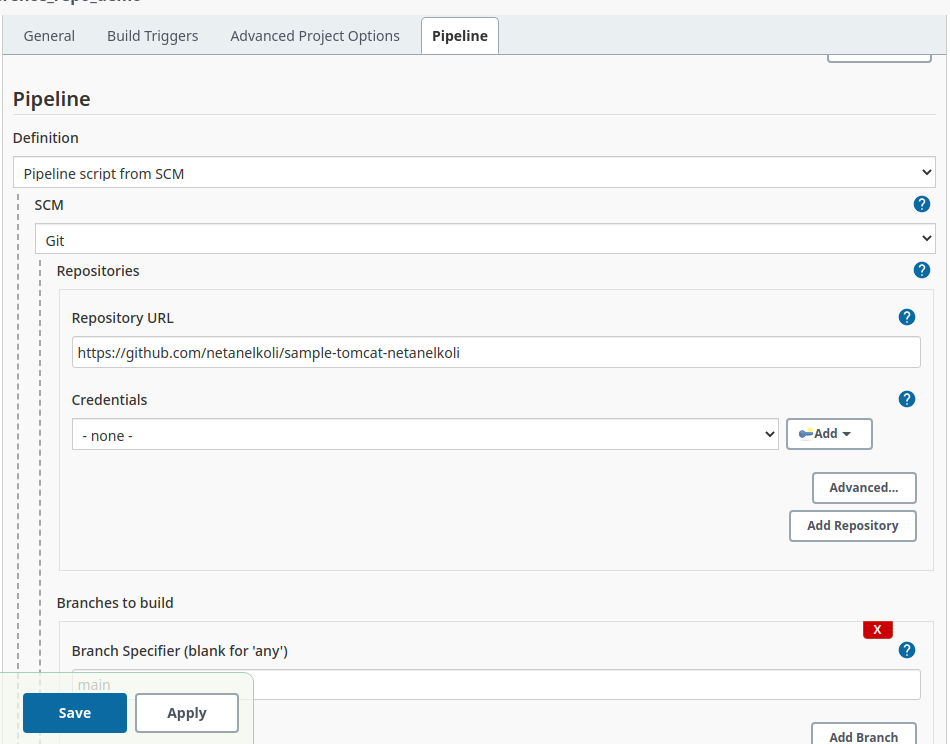
- In configuration page enter the following git values:
- Build the job for the first time.
- Wait for the build to finish. Go back to the terminal. Look at the .git directory on the FileSystem. It weighs about 11M!
- Let’s try to implement the solution – git reference repository to see how may decrease this “.git” directory size.
- Enter the Jenkins node.
- Create a main folder to hold all our git repositories as cache references:
- cd $JENKINS_HOME
- mkdir git_repo_references ; cd git_repo_references

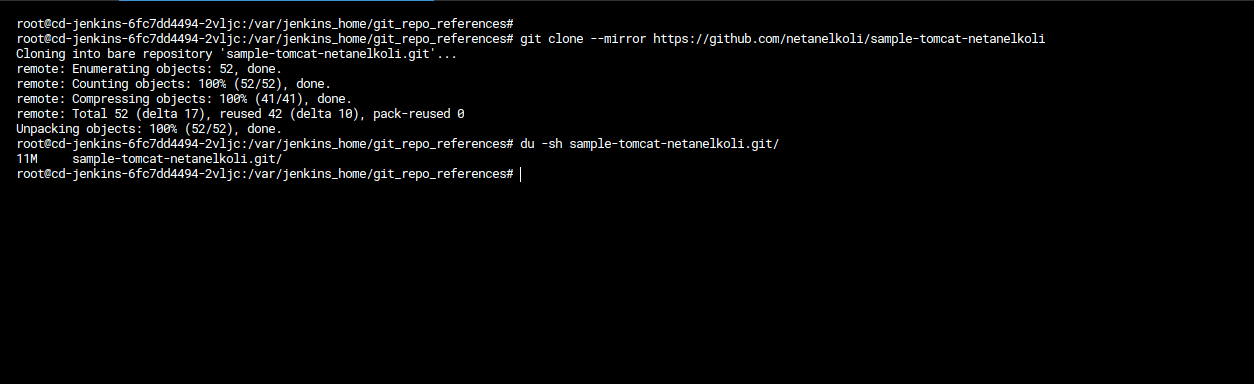
- Clone the git repo (when you use your own project, you may asked for git credentials):
- Git clone –mirror https://github.com/netanelkoli/sample-tomcat-netanelkoli.git
- ls -l sample-tomcat-netanelkoli.git/

- In Jenkins job configuration, got to the “Pipeline” -> “SCM” Panel, and create a new git “Advanced Clone Behaviours”:
- Disable “Fetch tags” (In case you don’t need git tags in part of your build), and enter the path to the git repo dir under the cache folder we created in step #2: “$JENKINS_HOME/git_repo_references/sample-tomcat-netanelkoli.git”
- NOTE; if you are using git’s behavior specify “refs spec” or configured a “refspec” in the git repositories field, make sure to also select the “Honor refspec on initial clone”.
- Click “Save”.
- Now, let’s test if our new configuration really works. Start a build of this git project, and enter the console output screen. We will see in the logs the “Using reference repository” line. NOTE: In order to see this change, you need to either delete the workspace dir manually, or to add the step “Wipe out repository & force clone”.
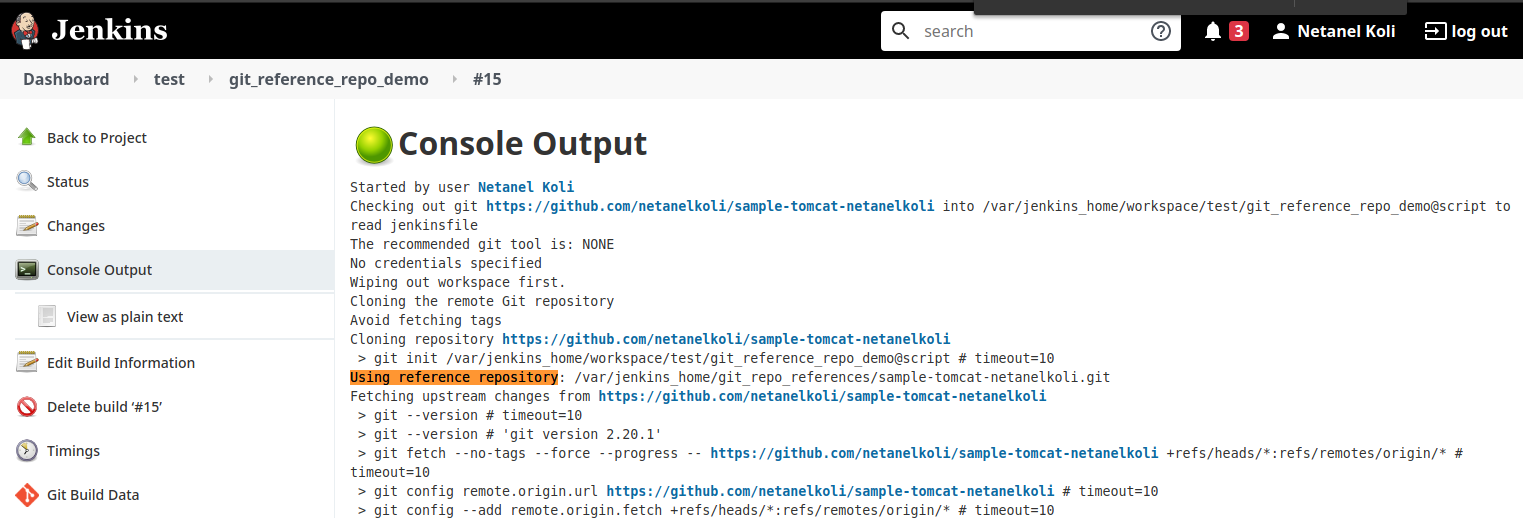
- Lets see it in practice on our FS. Earlier in step #4, our .”git” dir was 11 MB. Now let’s look if the size of it changed.
- cd $JENKINS_HOME/workspace/test/git_reference_repo_demo/
- du -sh .git – Notice “.git” dir is now only 176K! It works !!








Configure a Jenkins scheduled job to update cache repos
We configured Jenkins jobs git repository reference. However, our job is not really done yet.
The problem is once your original Git repos will increase (new features, files, etc.) the “delta” the Jenkins job will have to clone will increase as well. Therefore, we will have to configure some cronjob to fetch the repositories into the cache repos dir we created in step #2.
Demo Jenkins Job
| import java.io.File; import java.nio.file.Paths; //Specify the list of your git projects/repositories. final reposList = [<“repoA”>, <“repoB”>] final baseDir = appendTrailingSlash(“/var/jenkins_home/git_repo_references/”) // Cron job configurations – configured to run every day at 23:00 PM properties([pipelineTriggers([cron(‘H 23 * * *’)])]) pipeline { agent { label ‘<YOUR_NODE_LABEL>’ } stages { stage(“Pre-Checks”) { steps { script { for (repo in reposList) { def repoDir = baseDir + repo if (!Paths.get(repoDir).toFile().isDirectory()) { File dir = new File(repoDir) if (dir.mkdirs()) { println(“New dir: ${repoDir} successfully created!”) println(“Cloning relevant git repo…”) gitInitialClone(repoDir, repo) } else { error(“Failed to create dir: ${repoDir}. Exiting…”) } } else { println(“Directory: ${repoDir} already exists!”) } } } } } stage(“Git update”) { steps { script { for (repo in reposList) { def repoDir = baseDir + repo + “/${repo}.git” println(“Updating the git repo: ${repo}, located in ${repoDir}”) gitFetchPrune(repoDir) } } } } } } def gitInitialClone(repo_path, repo_name) { node(<YOUR_NODE>) { dir(repo_path){ println(“Git initially cloning repo: ${repo_name}”) sh “”” git clone –mirror https://github.org/<YOUR_ORGANIZATION>/${repo_name}.git “”” } } } def gitFetchPrune(repo_path) { node(<YOUR_NODE>) { dir(repo_path) { println(“Git fetch repo: ${repo_path}…”) sh “”” git fetch –all –prune “”” println(“Finished fetching git repo on ${repo_path}”) } } } def appendTrailingSlash(path) { return path.endsWith(“/”) ? path : path + “/”; } |
Notes:
- Make sure to switch all the <VALUES> with your own values.
- This job assumes the access to your repository is not protected with username/password. In case it is, consider adding the Jenkins withCredentials tool.
- It may be that a security issue will prevent the job from running. It is because we are accessing the File System files in this job. You can either approve the script in the Jenkins configuration panel, or uncheck the “Use Groovy Sandbox” option in the job configuration.

Conclusion
In this article we saw how using the git reference repository feature may help Administrators build a more effective environment. Not only does this reduce disk usage but it also affects network traffic reduction which is significant, especially in cloud environments. As discussed, this feature helped us at Argus Cyber Security to save up to 40% of our Jenkins disk space.
Adopting this feature and other similar features can help devops or other administrators to create a cleaner, more efficient, and self-maintained development environment.
References
https://support.cloudbees.com/hc/en-us/articles/115001728812-Using-a-Git-reference-repository
https://www.jenkins.io/doc/book/pipeline/multibranch/
https://www.unixmen.com/ncdu-ncurses-disk-usage-analyzer/



