External communication with Apache Kafka deployed in Kubernetes cluster
Introduction
At Argus, we strive to deploy all our data pipeline services as Docker containers managed by Kubernetes. This usually makes our lives much easier, and our products much more maintainable. But recently we had to dig deep into Kubernetes and Kafka – for a special use case where we wanted to expose Kafka outside the Kubernetes cluster – in order to communicate with other machines.
This tech post serves as a quick yet comprehensive article about communication methods with Kafka that is deployed inside a Kubernetes cluster. It assumes basic knowledge on Kafka, Docker and Kubernetes.
The use case
We use an analytics database deployed directly on VMs. The database consumes records from kafka that is deployed inside the Kubernetes cluster. This is a special use case since we usually deploy services and databases inside the Kubernetes cluster, and not on VMs.
The problem
Kafka is designed to store different partitions on different brokers, and the client must communicate directly to the broker that stores the desired partition – brokers cannot coordinate requests and are generally built to be very cheap. This is different from other distributed applications. In Cassandra for instance, each broker can receive any request, and serve as coordinator – collect the data from other brokers and return it to the client.
What we basically need is some way to pipe traffic from outside the cluster to each individual broker. This problem was already solved for in-cluster-communication using headless-service. Headless-service provides a stable network ID for each broker, this post by Alen Komljen further explains the concept. Unfortunately, in our special use case the desired communication channel is with a client outside the kubernetes cluster (K8s), and this cannot be solved with headless-service since the created identity only exists inside K8s. See chart below:
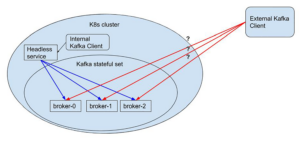
Figure 1: Headless service is only accessible inside the K8s cluster
(1) Possible solution: Kafka REST proxy
This is basically a workaround: instead of reaching the brokers directly, connect via REST API. This solves the problem, but creates an added complexity level to the system. Also, this solution is an overhead since Kafka is designed to have its clients aware of brokers state (the state is not communicated through the REST proxy) and communicate with brokers directly (not through an intermediary).
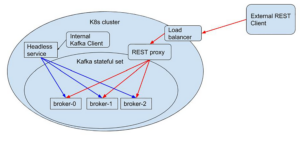
Figure 2: REST communication using REST proxy
(2) Possible solution: external NodePort service for each broker
This solution is supported by Helm’s official Kafka chart and is the default when configuring communication between Kafka brokers and client applications outside K8s. Basically, a NodePort service is created for each broker where the nodes provide unique ports for direct communication between clients outside K8s. The routing is done by K8s when accessing node IPs (K8s runs on the background of each node and controls the routing). For example, if broker `kafka-0` has NodePort service configured with port A, all nodes in the K8s cluster listen to port A, and forward network packets to broker `kafka-0`. This means that each broker gets a unique port for external access.
The biggest drawback here is that node IPs can change frequently, especially when using a cloud platform. Nodes used for K8s are meant to be easily replaced and therefore their IPs are usually unreliable (they typically change at unknown time intervals). The need to re-configure the external clients is not easily solved ** and can lead to disruptions and even downtime. In addition, for dev environments our K8s nodes are GCP’s preemptible VMs (VMs that live for at most 24 hours). Therefore this does not solve our problem.
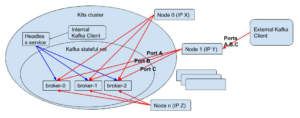
Figure 3: Using NodePort – route using the nodes
** There are solutions for syncing Node IPs with DNS records, this project does that, for example.
(3) Chosen solution: Load Balancer for each broker
Because of the drawbacks described in the previous two solutions, we decided to create a Load Balancer for each broker. This means that each broker will receive a unique IP used for communicating with external clients that is reachable at anytime. The load balancing IP of each broker provides the direct communication needed – load balancers are deployed as K8s services (you can read more about load balancing in GCP). Unfortunately, when we chose this solution, there were a few minor issues that needed to be solved:
At startup time, each broker must get its bootstrap servers (bootstrap servers are basically the addresses that route to the broker – read more about Kafka bootstrap.servers), so it must be pre-configured with its external IP. This can easily be resolved through an alpha feature of K8s (`dns.alpha.kubernetes.io/internal`) *. However, for the sake of stability we do not use alpha features and needed to solve it differently. We did that by creating a new subdomain on our DNS, dedicated only to Kafka external Load Balancers. So this way we could pre-configure each broker’s bootstrap servers using the DNS, and then configure the DNS routing IP to the desired Load Balancer IP address (after the Load Balancer is ready). We had to tweak the original helm chart(version 0.9.0) to achieve this, the relevant code follows:
stetefulset.yaml
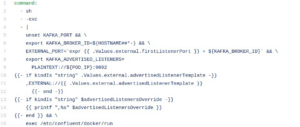
Figure 4: code that was changed in `service-brokers-external.yaml`

Figure 5: code that was added to `values.yaml`
In addition, we didn’t want to expose Kafka outside our GCP project (read more about GCP projects), so we added an annotation to only allow traffic that comes from the same GCP project. You can read about it here.
cloud.google.com/load-balancer-type: “Internal”
* The external-dns chart could also work, you can further read about it.
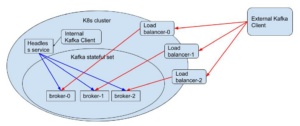
Figure 6: Load balancer for each broker
Summary
We solved the problem and achieved a stable connection from our external database to the Kafka brokers using load balancers. Keep in mind that different use cases might require different solutions than what worked for us. In case of onsite deployment, for example, the second solution might be the most suitable. If you want to read more about different ways to deploy Kafka on Kubernetes, I suggest this article by Gwen Shapira. Feel free to comment below if you have any questions or thoughts, enjoy!